Cloud Computing Outlook Weekly Brief
Be first to read the latest tech news, Industry Leader's Insights, and CIO interviews of medium and large enterprises exclusively from Cloud Computing Outlook
Introduction  Edward Wustenhoff, CTO and Head of Product Development, Burstorm
Edward Wustenhoff, CTO and Head of Product Development, Burstorm
About 7 years ago, when I was in charge of the design and operation of a large HPC cluster, I was asked by my mentor “why are you not using AWS?” I had to agree, our workloads were distributed over a long queue with different characteristics and using compute andstorage as a service seemed a very attractive model for parts of it. However, at that time there were many technical reasons we could not embark on this trip.
A lot has changed and ever since that moment I’ve been on a quest to find out how to determine the right model for consuming any type of Compute, Storage, Datacenter and Network. This article describes some of the key considerations that would drive a decision to run a typical HPC workload in the cloud.
The Framework
To help scope and manage the decision process I use the following framework:
Scope: All aspects of Compute, Storage, Datacenter and Network.
Aspects: Availability, Security, Performance, Economics and Change.
These cover all areas that need to be considered to come to the right consumption model of services.
As a general rule I use the level of commitment and control as a compass to determine what should be closer to in-house. For example, if I can commit to a workload for 30 years I should possibly consider building a Datacenter as that is more a real-estate duration. Conversely if I don’t need control of the chip architecture and want to only sign up for a week, I’d probably benefit from a service model.
With this framework in mind I will be illustrating some of the key decision aspects to run HPC in-house vs. in the cloud.
Compute
An advantage of HPC over common infrastructures is that the nodes are very homogeneous and don’t require high availability. Those aspects generally lend themselves well to be delivered in the cloud. The management and scheduling components are more sensitive but are still relatively easily deployed on third party services.
A key challenge for compute lies in the availability of volume and size (core count and RAM). Few providers can deliver large quantities without notice. Even AWS has controls that limit the number of instances being spun up within a certain amount of time.
When doing things in-house, it’s clear: you have or you don’t have the capacity. In the cloud the decision as to when to spin up and/or spin down nodes becomes an additional feature that the scheduler should consider because dynamic capacity affects economics significantly.
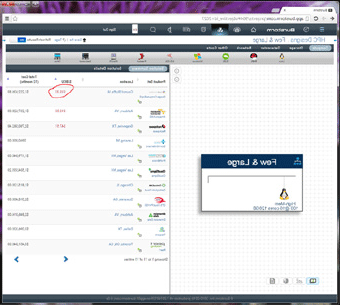
HPC nodes often benefit from large core counts and memory to enhance performance of data processing within a node. Not many cloud providers have largememory size systems available, let alone on-demand. Although this seems to be an inhibitor, I would argue that there is real opportunity to solve the core/RAM capacity issue by a larger volume of smaller nodes. To illustrate why consider this:
The picture here shows the options and economics of a “few larger” nodes to help illustrate the difference with “many smaller” nodes.
Note the $/BCU number that represents a normalized cost based on performance capabilities. The numbers of options are small. Let’s compare that against this
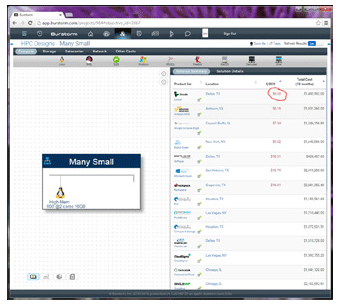
This pictureshows the economics of “many small servers” with the same total cores and RAM. The $/BCU is much lower. Meaning the cost per performance “tick” is lower. Therefore, if your workload can be processed by more yet smaller systems, running in the cloud is a cost effective approach. Also note that there are a lot more options available.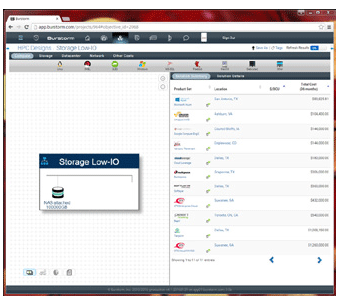
Another consideration is thatperformance in the cloud, as you can see in the above tables, is not always the same for similar instances between vendors and on top of that can change over time. So you need to do your homework well.
Storage
In my experience the movement and transformational aspect of data in an HPC cluster is the most critical challenge to solve as it significantly affects performance, security and cost.
Running in the cloud forces additional attention to data security and encryption, which has a negative impact on performance. Moving data into the cloud, between clouds and within the cloud itself is complex and relatively slow. We designed our queue with this aspect in mind and in doing so revealed early opportunities to leverage the cloud. Particularly the delivery of static content to customers is a good first target.
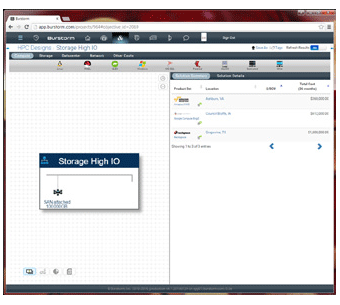
To illustrate the availability and cost of “low IO” versus “high IO” (SSD based) of 100 Terabyte of storage space consider the following:
 Note the still significant cost for relatively slow storage. Often too slow for in-queueprocessing.The next picture shows some of the SSD based “high IO” storage in the cloud today
Note the still significant cost for relatively slow storage. Often too slow for in-queueprocessing.The next picture shows some of the SSD based “high IO” storage in the cloud today
Very few options and at a significant cost. This, combined with the possible security and movement restrictions make data intensive HPCs a big challenge in the cloud in my opinion.
In addition, the realization that business critical data is hosted at a third party, which is also hard to move, can become a critical inhibitor.
You have to make sure to understand the data volume and movement through your queue very well when considering moving to the cloud.
Conclusion
The cloud is a real opportunity to enhance HPC capabilities but there is still a real technology gap between what is available in the cloud today and what is needed to be successful. However, more and more technology solutions are becoming available and so it becomes more and more an economical decision. As this trend continues consider this:
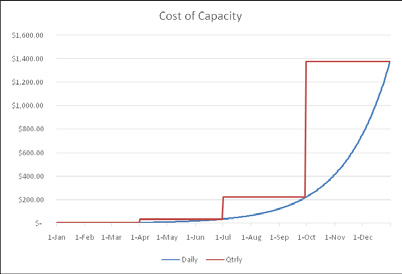
Even if you would do exactly the same in-house or in the cloud, there is a significant economic benefit when you are able to have capacity available “just in time”.Figure 5: Cost of capacity
Figure 5shows the delta between the cost of having to add capacity a quarter ahead of the actual consumption (typical in-house scenario) and the cost would you be able to do so on a daily basis. It’s significant: this model shows a 40 percent difference in cost over 1 year . This also assumes continual growth. Imagine what happens if growth would stall mid quarter.
Although many technical challenges remain, it is clear that using cloud services for HPC workloads can deliver great economic benefits. The providers are continually innovating to eliminate barriers to adoptionand I expect a lot of new options in the near future. HPC consumers should follow the trends closely and possibly even adapt workloads so they can take advantage of this new compute and storage consumption model.











![Box [NYSE:BOX]: Share. Manage. Collaborate.](https://www.cloudcomputingoutlook.com/company_logos/2gac4.box300.gif "Box [NYSE:BOX]: Share. Manage. Collaborate.")


